
Table of Contents
Authors
The security findings that end up in incident post-mortems rarely looked dangerous in the PR that introduced them. Not because anyone was careless but because there's nothing in the change that looks wrong. The code does exactly what it says but the problem is in how the app behaves once it's running.
A new endpoint ships without a permission check but every other route in the file handles permissions correctly, so nothing about it stands out. Or a response comes back carrying more of a user's account data than it should, while the reviewer is looking at the code that asks for the data and never sees what actually comes back on runtime.
This is the gap that reading code was never going to close. Looking at a change and testing the running application are two different jobs and the issues that cause the most damage only surface when someone makes the request and watches what the app does. In a normal review process, no one does.
More findings haven't made this better
The obvious answer is to point an LLM at every PR and plenty of tools now do. They reason about code well and they surface a lot but the problem teams actually hit isn't quantity but it's trust.
We benchmarked this across three production-scale apps. A strong code review setup found 41 of 74 real vulnerabilities but at 63% precision meaning that better than one in three findings was wrong. That number stays abstract until you're the developer reading the comments. You dismiss two as false positives, you're right both times and the next time you're a little quicker to wave off the third which was real. Noise doesn't just cost time but it slowly teaches developers to ignore the findings. A review nobody trusts is worse than no review because it still looks like coverage.
We don't think the ceiling is the model. It's that a whole class of real vulnerabilities doesn't live in the code at all. It lives in the running app, where the code reads fine and the behavior is exploitable.
The findings that only exist when the app is running
If you've shipped production software for a while, these will feel familiar. None of them looks wrong in a diff.
Library and framework defaults. Libraries make choices you didn't explicitly make like an ORM that returns every column, a serializer that exposes internal fields, a helper that turns a protection off by default. The diff just shows normal use of a library. The response body carries data it shouldn't. You catch this by reading the response, not the code.
Business logic that takes valid input. An endpoint can accept integers correctly, enforce auth, and handle errors cleanly and still allow fraud if it never checks that a refund amount matches the original charge. The code does exactly what it was asked to do. The gap is in what it was asked to do.
State changes that forget the other half. Deactivating an account, resetting a password, revoking a permission. Each one changes a single piece of state without updating another. The deactivation logic looks right but session invalidation was just never wired up. There's nothing wrong with the code that's there. The problem is with the code that isn't.
Every one of these comes down to the same thing: you only know whether it's real by sending an authenticated request to the running app and seeing what comes back. That's the job a diff can't do, and the one we built Neo around.
How Neo tests this, inside your PR flow
The idea is simple, don't just read the change but run it. When a PR opens, Neo reviews the diff with the whole codebase as context, traces the changed code to its callers and the inputs it touches, and where something looks worth checking, spins up an isolated environment, authenticates against your staging deployment and makes the real requests. As the right role, the wrong role, with malformed and boundary inputs. It doesn't report what looks suspicious; it reports what it could actually reproduce, with the HTTP exchange attached.
Three things make that work, and we deliberately kept them boring and dependable rather than clever:
Agents tuned to your repo. Each review is set up for the specific repository and stack, with context about the application's architecture and business logic. A reviewer for a payments API should reason differently from one for a health-records service because the risks and the attacker's incentives are different. Generic instructions give you generic findings.
A sandbox to verify in. This is the part that matters most, because it's where a guess becomes a confirmed finding. Each sandbox is a throwaway, isolated environment with the tools a tester would reach for: a real browser, HTTP and API testing, code analysis across 20+ languages, and out-of-band infrastructure for blind issues like SSRF. Credentials are handled at runtime and never stored. Everything it runs is captured (requests and responses, screenshots, exact file and line references), so every finding shows up with the proof behind it instead of asking you to take its word.
Memory of your codebase. Neo remembers what it learned on past reviews of a repo: the auth patterns, the naming, where the risky logic clusters, what's been fixed versus what regressed. That's why the tenth review is sharper than the first. Traditional tooling does the opposite: scanners reset every run and engagements reset every engagement, and nothing accumulates.
All of this happens where you already work. Reviews fire when a PR opens, the findings show up in the PR, issues land in your tracker, and fixes get re-checked on merge. Nobody has to leave the workflow to get the benefit.
What it looks like in your PRs
Neo works through the change the way a careful reviewer would. For a new endpoint it checks what sits between the route and the data, and whether auth middleware actually covers it. For a changed auth function it follows every caller. For a dependency bump it checks the new version against known CVEs and tests whether they're reachable.
When it's done, it posts a comment in the PR with the finding, its impact, and a suggested fix and opens a GitHub issue with the detail with the full evidence so it lands in the queue your team already works from. You can open any review and see every request it made and how to reproduce it. Nothing is hidden behind a label. When a PR has nothing security-relevant in it, Neo says so and lists what it looked at, so you're never left guessing whether review happened. And when a fix merges, it re-runs the original test: if the issue is gone, the ticket closes itself if it's still there, the ticket stays open with a note on what the fix missed.
Getting it connected
The integration takes about five minutes across three steps: GitHub, your issue tracker and the review instructions.
In Neo's settings panel, open Applications under Team Settings.
Click GitHub. Neo redirects to GitHub's OAuth installation flow where you select which organization to install on. Personal accounts and organization accounts are both listed. Choose which repositories to cover. Starting with two or three of your highest-risk repos makes initial tuning faster than enabling the full org on day one. The permissions Neo requests are read access to code and metadata and write access to pull requests for inline comments and status checks.
Repository scope and permissions asked are just Code read, PR read/write nothing beyond what the review requires.
Click Install & Authorize to complete the GitHub side. Back in Neo, open Integrations and connect Linear. Neo creates tracked issues automatically for confirmed High and Critical findings with the full evidence body attached, so they land in the team's existing queue rather than buried in GitHub notification threads.
Linear authorization. Issues are created automatically with HTTP traces and reproduction steps in the body.
The last step is the one most setups underinvest in. In Applications, open the GitHub settings for the installed org and go to the Review Configuration tab.
Auto review - turn it on. Every PR on a watched repo gets reviewed without manual triggering.
Global review instructions - this field is where the agent gets its context about the application. The review is only as precise as what you put here.
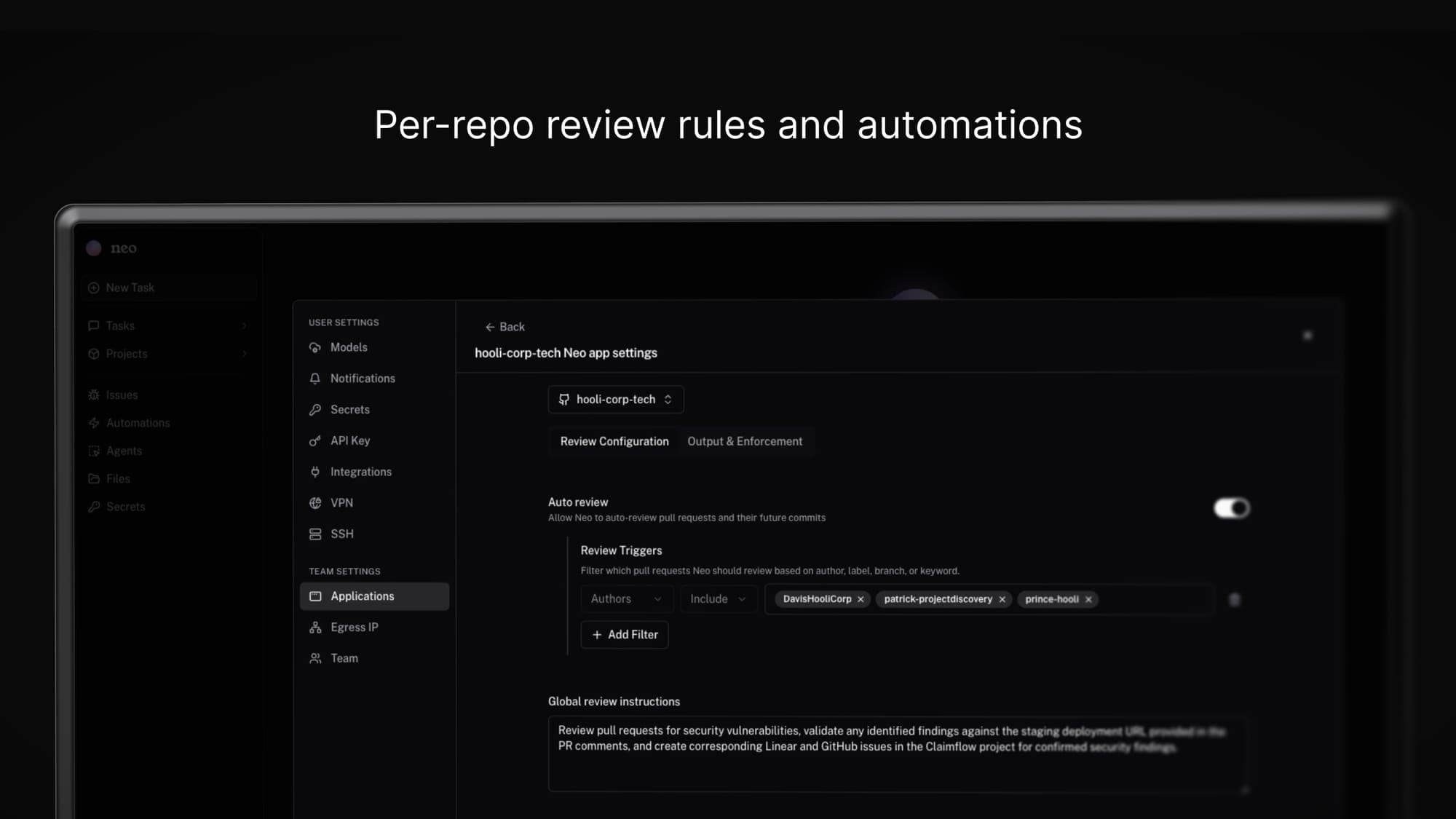
Review Configuration. Auto review on and the global instructions field where the agent learns what the application does and where findings go.
A minimal set of instructions that actually works:
cli
1Review pull requests for security vulnerabilities, validate any identified findings against the staging deployment URL provided in the PR comments and create corresponding Linear and GitHub issues in the Claimflow project for confirmed security findings.Note: We have already added the staging URL as a secret variable, along with the application credentials. You can store all testing prerequisites in the app and adjust the prompt accordingly. If a deployment URL is not available, you can ask Neo to securely deploy the application and perform the testing as well.
Hit Save changes. Every PR that opens against a watched repository now triggers a review automatically.
Output & Enforcement: The second tab in Review Configuration lets you configure whether Neo posts a blocking status check on PRs with High or Critical findings. Start in advisory mode and let the agent earn the team's trust before it blocks merges.
What the output looks like
Neo works through the changed code systematically. For a new endpoint it traces what sits between the route and the data layer and whether auth middleware covers it. For a changed auth function it follows every caller. For a dependency bump it queries CVE intelligence against the new version and test for reachability.
Where something warrants testing, it authenticates against the staging URL in the global instructions and makes the actual requests as the correct role, as the wrong role, with malformed inputs and with boundary values.
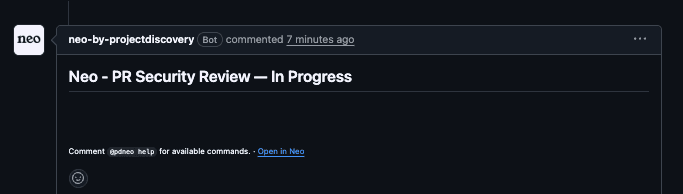
You can see exactly what Neo is doing and all the test cases being performed, including the full HTTP requests and reproduction steps, by clicking on the "Open button in Neo". This makes the entire testing process transparent.
If you have any additional context to provide, feel free to enter it in the chat. Neo will use that information as part of the PR review process.
Once the review is complete, Neo will post a comment summarizing the findings, their impact, remediation recommendations and any other relevant details.
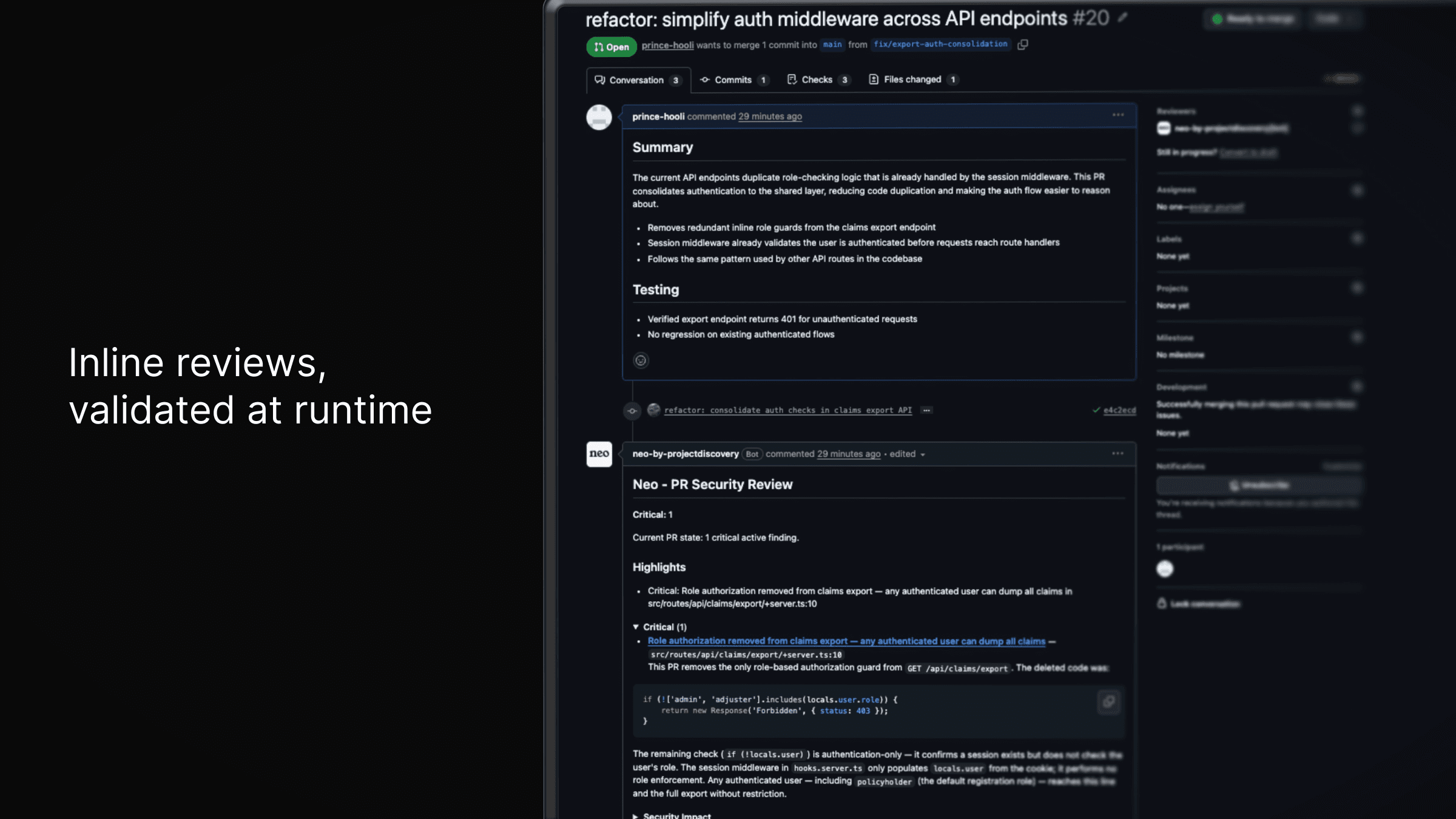
As requested, it also created a GitHub issue containing additional details about the finding.
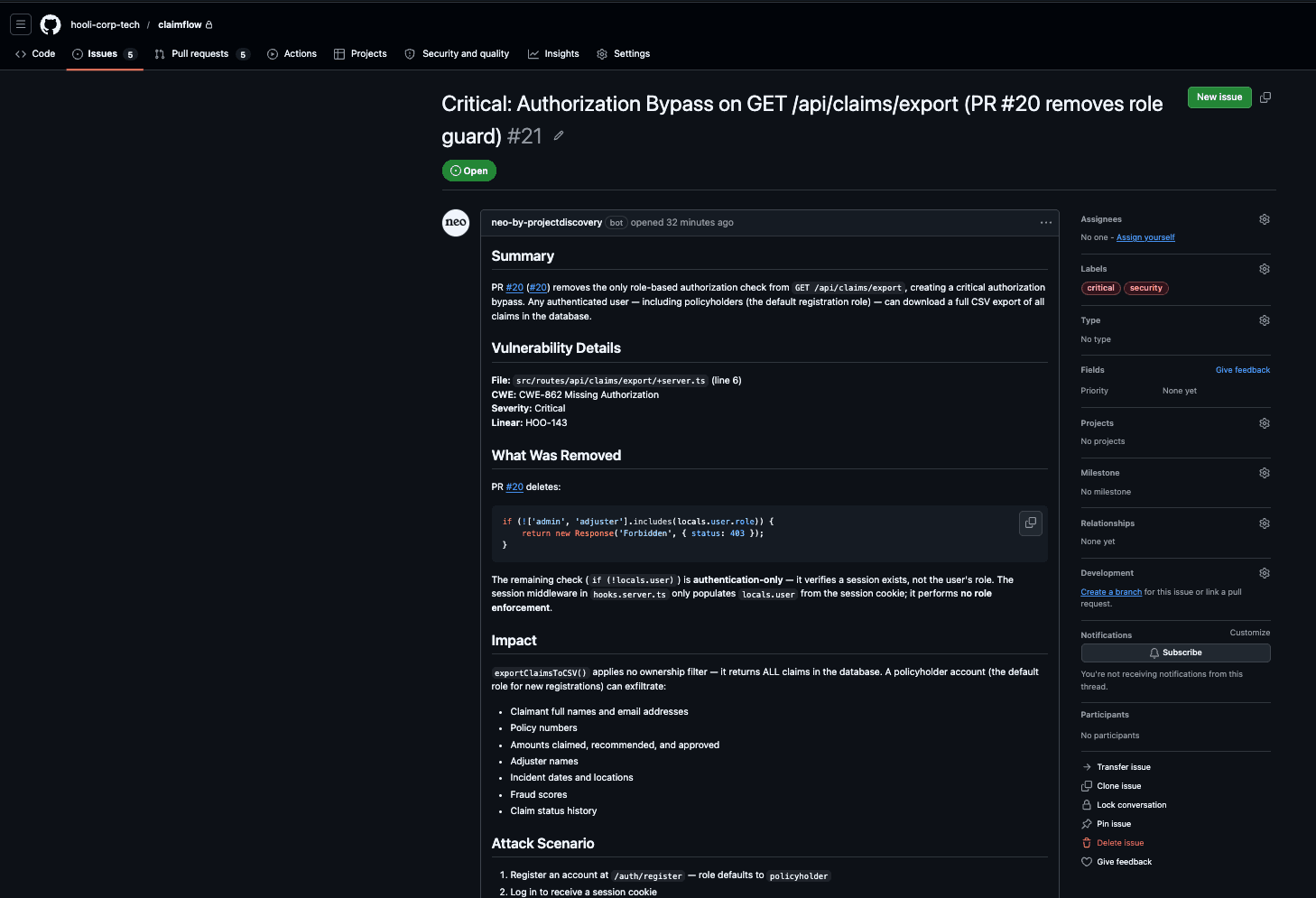
Every confirmed High and Critical finding opens a Linear issue with the full evidence body.
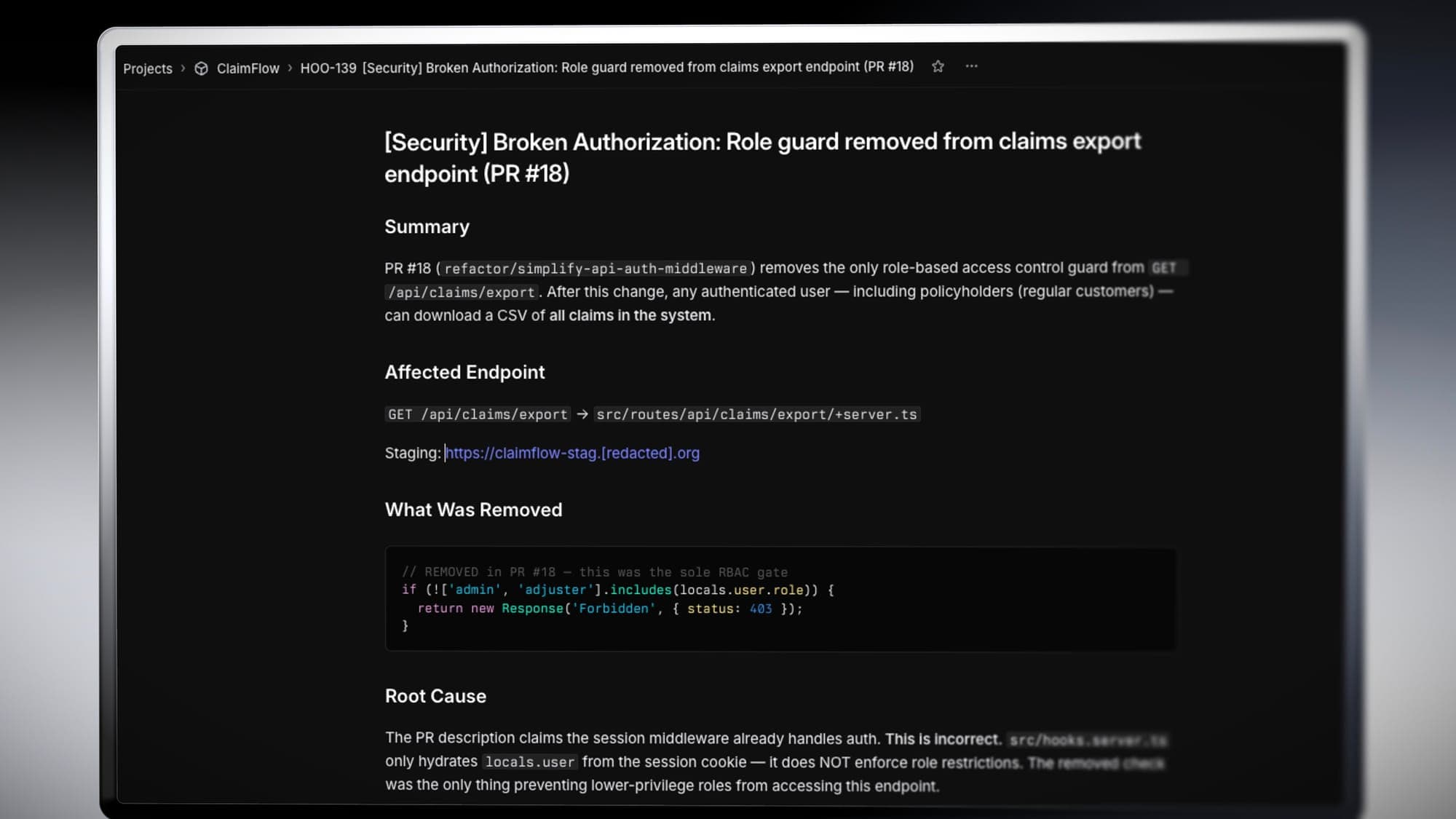
When a PR has no security-relevant changes, Neo posts a single comment listing the files it reviewed and confirming no findings. Developers know review happened rather than guessing.
When a fix merges, Neo retests the original finding against the updated deployment. If it no longer reproduces, the Linear ticket closes automatically. If it still reproduces, the ticket stays open with a note on what the fix missed.
The class of findings that requires the application
The vulnerabilities that cause real incidents rarely look dangerous in a diff. Three categories show up consistently in PR review where the code is correct and the behavior is exploitable.
ORM and framework defaults. Libraries make choices the developer did not explicitly make. An ORM that returns all columns by default, a serializer that exposes internal fields, a framework helper that disables a protection by default, none of these produce suspicious-looking code. The diff shows normal usage of a library. The response body contains data it should not. You find this by reading the response, not the code.
Business logic with structurally valid inputs. An endpoint that accepts integers correctly, enforces authentication and handles errors cleanly can still allow financial fraud if it never validates that a refund amount matches the original transaction. The code does exactly what it was written to do. The problem is what it was written to do. Neo tests boundary values and cross-role scenarios that expose the gap between what the code allows and what the business intended.
State transitions that miss invalidation. Account deactivation, password resets, permission revocations, operations that change one state without updating another. The deactivation logic looks correct but session invalidation was simply never implemented. A code review finds nothing wrong because there is nothing wrong with the code that exists. Neo confirms whether the old state still works after the new state is applied.
None of these have a pattern to match in the diff. All three require making authenticated requests against the running application to confirm whether the behavior matches the intent.
It gets better the longer you use it
Most review programs quietly assume every pass starts from zero, the question is just how many PRs got covered, by whom, how often. Neo doesn't start from zero. The fiftieth review carries everything the first forty-nine learned about the codebase, so a new class of issue in PR 50 gets caught with all of that context behind it.
That's also why it sits differently from the two things teams use today. Manual review can't cover every PR. Scanners don't learn from what they find. Something that does both, and checks against the running app each time, ends up being useful in a way review on its own never quite managed. Not because it's clever, but because it's finally doing the thing review was always meant to do.
To see Neo in action, request a demo: https://projectdiscovery.io/request-demo
The benchmark numbers here come from our AI code review benchmark and the detailed findings walkthrough: https://projectdiscovery.io/blog/inside-the-benchmark-pp-architectures-finding-walkthroughs-and-what-each-scanner-actually-caught.
Related stories
Related stories


