

Reconnaissance is an important step in identifying and building your organization's attack surface or targeted assets. Web crawling is a prominent reconnaissance technique that allows you to gather information by automatically traversing and extracting data from web pages. However, this process often results in unstructured data that contains countless URLs and parameters, making it difficult to identify unique endpoints, parameters, and fields for use in automation or reconnaissance pipelines. There should be an easier way.
We’d like to introduce Katana – a Golang-based CLI tool developed by ProjectDiscovery that employs headless browsing to efficiently crawly and spider web applications while simultaneously supporting field extraction. With Katana's field extraction capabilities, you can easily filter and utilize your output as input for other tools or incorporate it into your reconnaissance pipeline.
In this blog, we'll discuss the intricacies of using Katana for web crawling, performing field extraction, and using the tool's output to enhance your reconnaissance pipeline.
Introduction to Katana
Katana is an open-source tool that supports standard and headless modes, allowing for JavaScript parsing and crawling. Katana also has customizable automatic form filling, preconfigured field and regex-based scope control, and configurable output options, including predefined fields and support for multiple input sources such as STDIN, URL, and LIST.
With Katana, you can perform field extraction and use the output to build your recon automation pipeline using the ProjectDiscovery tools suite and other widely used recon tools. You can directly install Katana using Binary or Docker. More information can be found at: https://github.com/projectdiscovery/katana
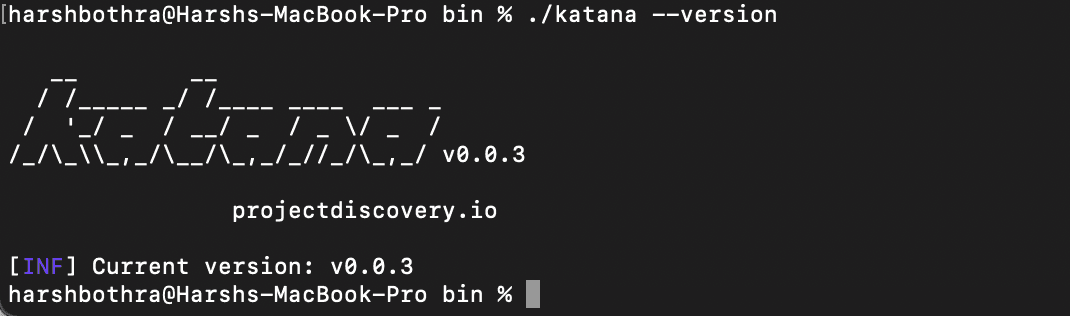
Once you have installed Katana, run the following command to verify the installation:
Command: katana --version
What is Field Extraction?
Field extraction is a process that allows the extraction of specific data fields from unstructured data to make it more useful for further processing and utilization. It helps to reduce the amount of data that needs to be processed by focusing on specific fields of interest. This can be especially helpful in security-related tasks such as reconnaissance, where identifying key pieces of data, such as endpoints or credentials, can be critical for identifying and mitigating potential threats.
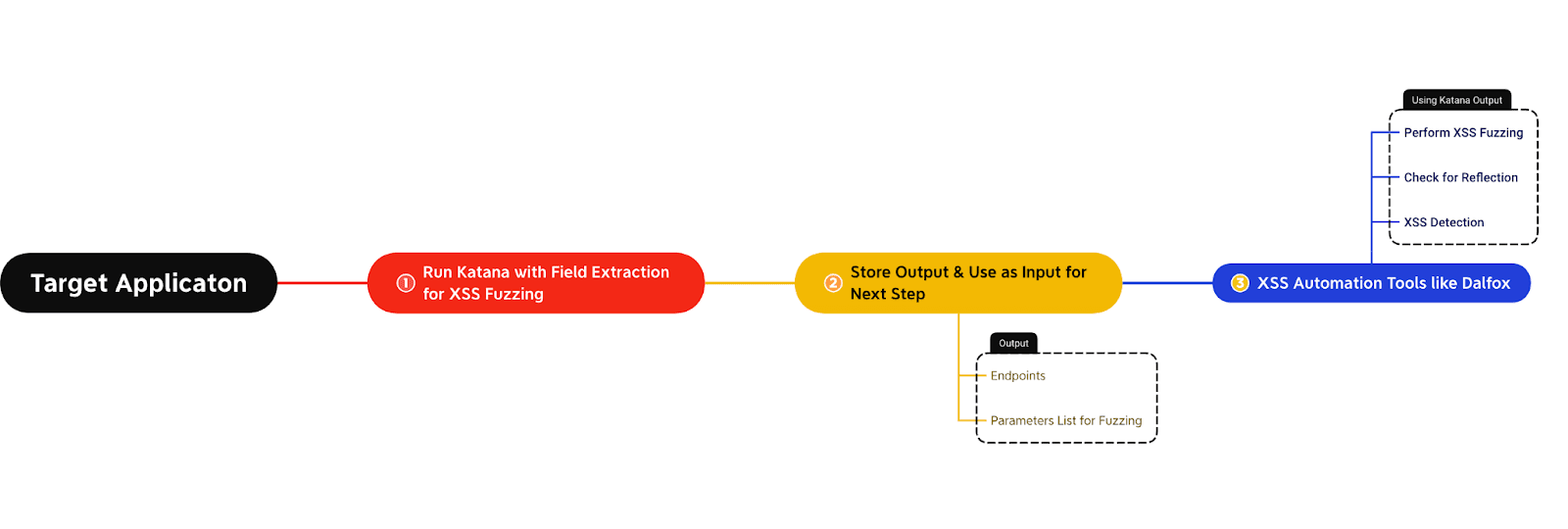
For example, let’s assume you want to perform automated fuzzing for Cross-Site Scripting (XSS) vulnerabilities. In this case, you can attempt to extract the various unique parameters from the output and fuzz the uniquely identified endpoints with these parameters containing XSS payloads to check for potential reflection. The below flow diagram explains this use case:
Using regex rules, Katana allows the custom fields to extract and store specific information from page responses. These custom fields are defined using a YAML config file and are loaded from the default location at $HOME/.config/katana/field-config.yaml. Alternatively, you can use the -flc option to load a custom field config file from a different location.
Custom field extraction using Katana
Default field extraction using Katana
Katana supports multiple default fields such as url, path, fqdn, rdn, rurl, qurl, qpath, file, key, value, kv, dir, udir which can directly be extracted without requiring to use a custom regex. You can check the table provided at https://github.com/projectdiscovery/katana#-field to understand what each field identifier does.
Let’s see this in action using following steps:
- First, run the tool with no additional feature flags to see how the data is returned.
Command: katana -u https://yahoo.com
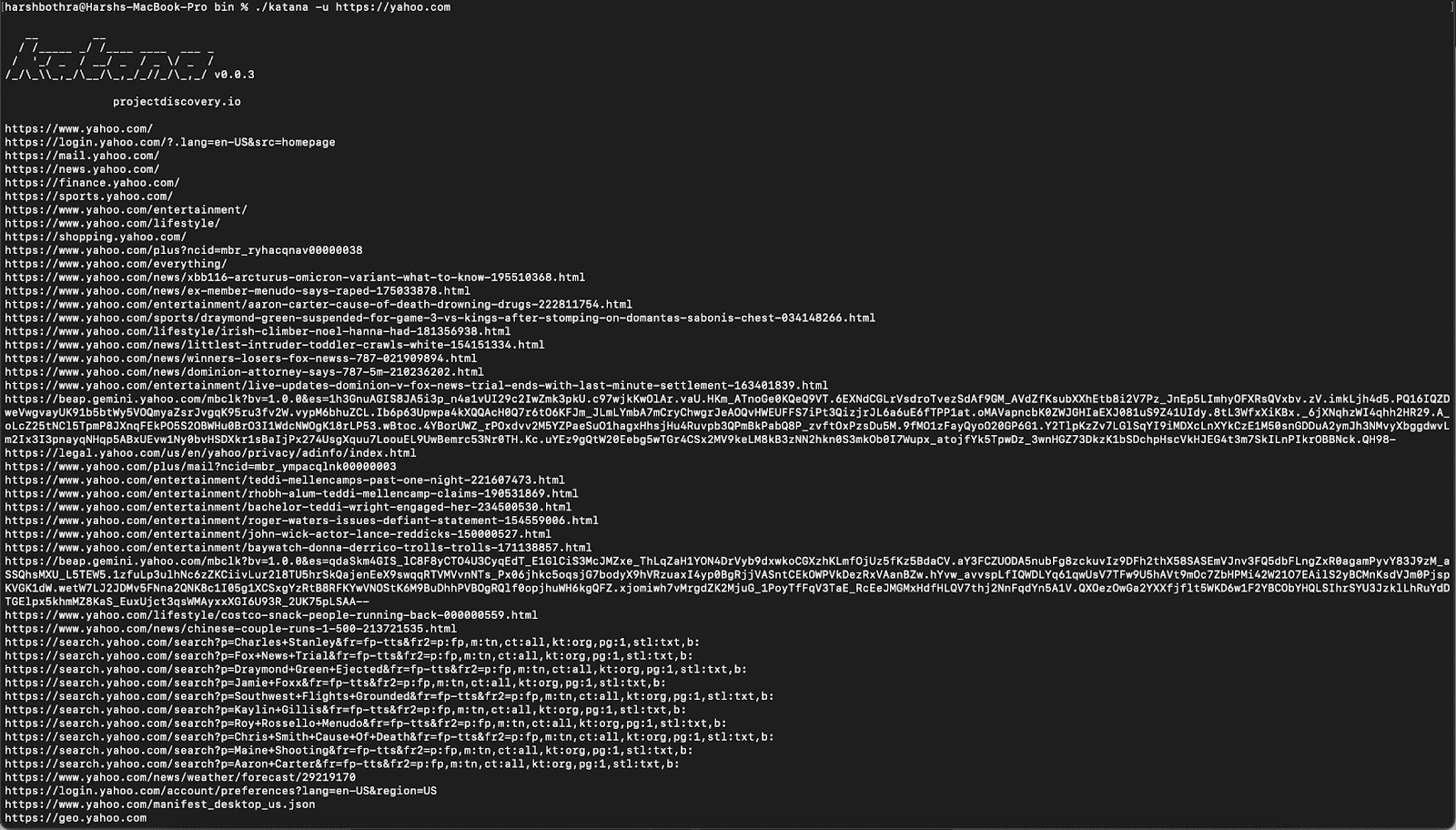
2. This screenshot of the data at the end of the run shows how many endpoints have been returned. The tool has returned data containing approximately 205 endpoints that may have duplicity or otherwise contain data that is not of interest.

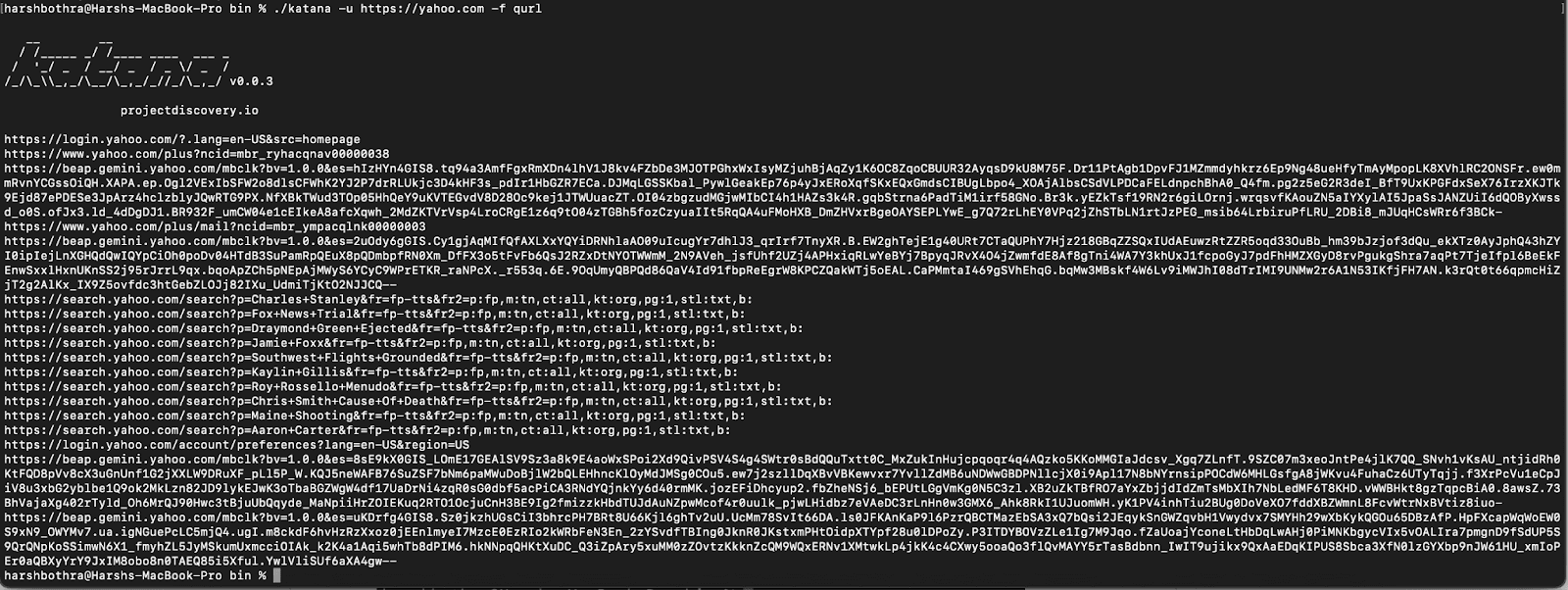
3. Now, run the tool using default field extraction trying to extract the qurl field. This extracts the URL including query parameters.
Command: katana -u https://yahoo.com -f qurl
4. Now, the output only contains endpoints having a query parameter and the output has been reduced from 205 endpoints to 25.

User defined custom field extraction using Katana
Katana also supports custom field extraction with user defined regex.
- First, run the tool with no additional feature flags to see how the data is returned.
Command: katana -u https://tesla.com
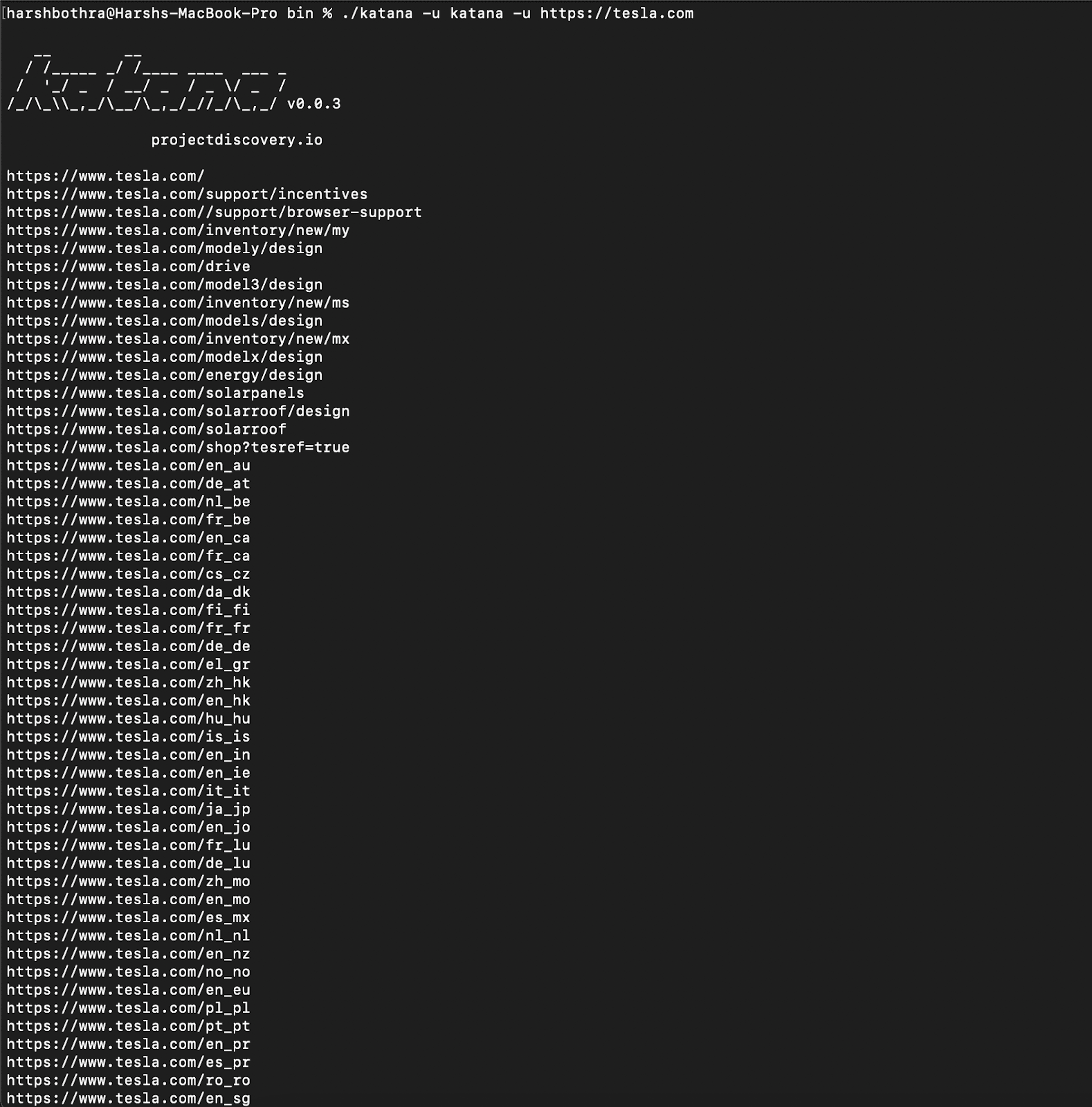
2. This command returned data containing approximately 1033 endpoints that may have duplicity or contain data that is not of interest.

3. Now, run the tool using field extraction to extract the email field using the below command:
Command: katana -u https://tesla.com -f email
4. Now, the output only contains potentially extracted email addresses.
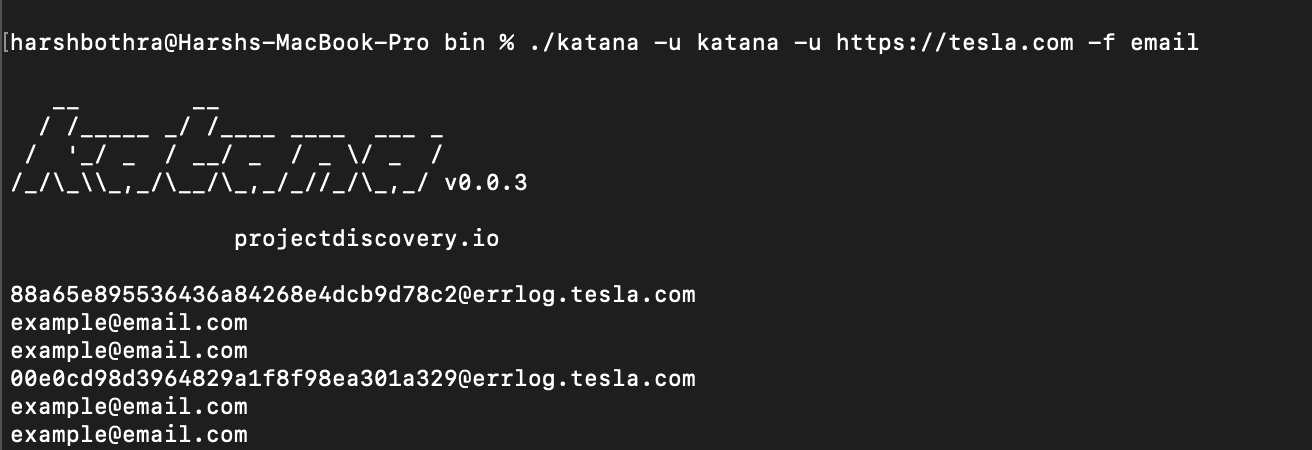
Alternatively, you can use the -flc option to load a custom field configuration file from a different location using the following steps:
- Create a regex file as mentioned in the following documentation: https://github.com/projectdiscovery/katana#custom-fields
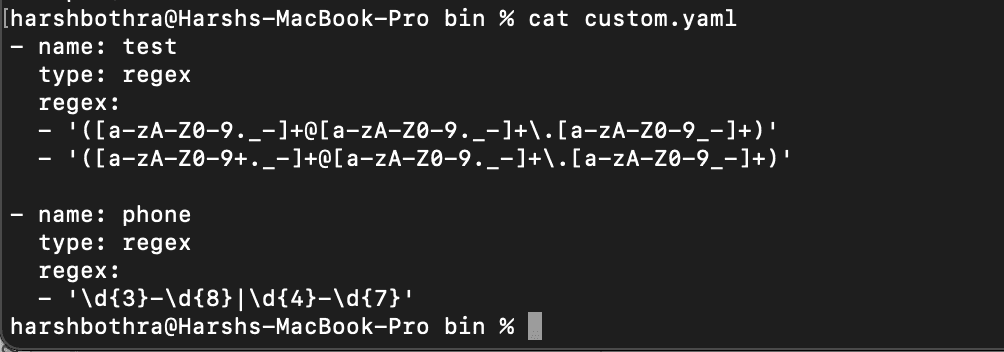
2. Run the following command to load the configuration file from a user-defined location:
Command: katana -u https://tesla.com -flc custom.yaml -f test
3. The desired output, "email”, based on the regex, is returned.
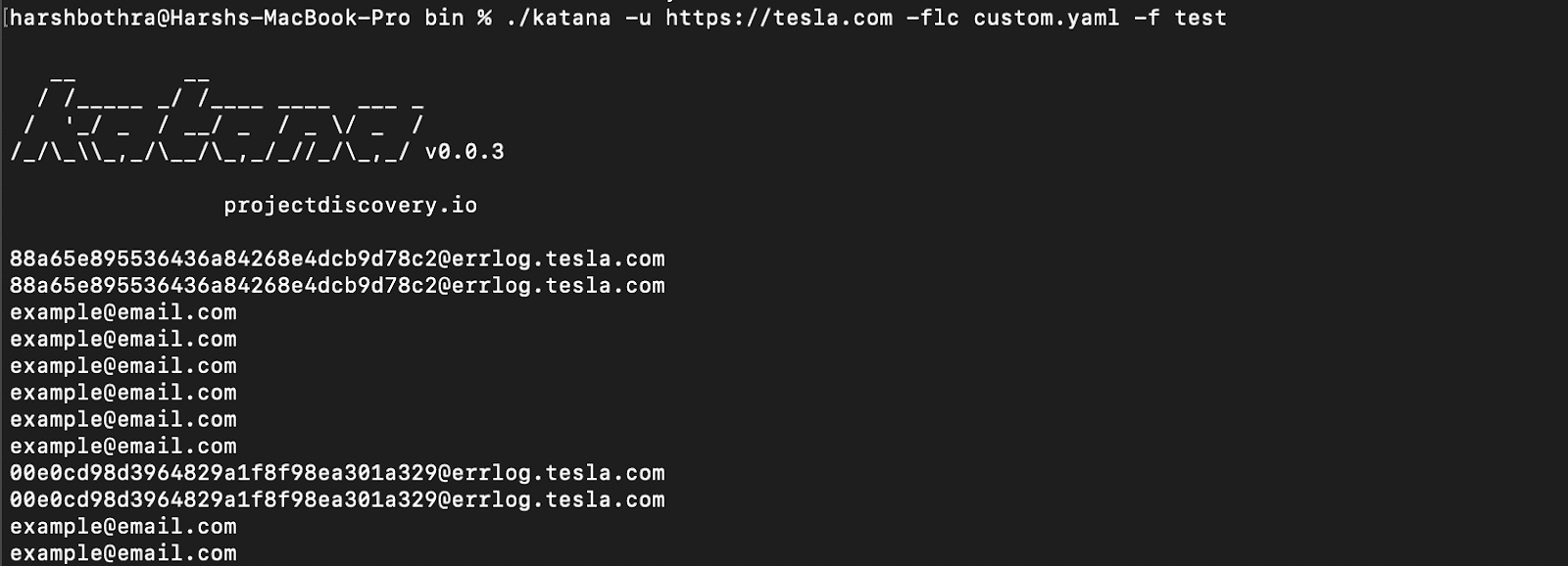
Note: In the above command, you need to supply the config file value (.yaml) in the -flc parameter and the “name” used in the config file in the -f parameter to get the desired output.
Conclusion
Katana is a powerful tool that can make web crawling easier, more efficient, and more customizable. Its advanced field extraction capabilities allow users to fine-tune the output to match their specific needs for further processing. Whether you're a security researcher, a data analyst, or just someone looking to extract information from the web, you'll likely have some good use-cases for Katana.
Give it a try!